Features:
Scraping Nevada
The Three Stages of Scraping and the Form from Hell
Finding precinct-level election results from Nevada isn’t the problem. Getting them is the problem.
If you’ve been writing scrapers long enough, chances are you’ve come across what could be fairly called “the form from hell.” It usually is found on a URL that ends .aspx and features paginated links that have a JavaScript URL that performs a postback request to the server. In other words, not something that you can just iterate over using a unique ID for every record.
That’s the kind of site the Nevada Secretary of State has for its database of precinct-level election results, and this is the story of how I retrieved them for OpenElections, a Knight Foundation-funded project that’s building a database of certified election results from all 50 states. The story goes through some of the usual stages of scraping: denial, annoyance and finally acceptance. It ends with a clean copy of every precinct-level result from 2004 through 2012, and I’m hoping the state adds 2014 results soon.
Denial

“This isn’t a problem,” I told myself after I first found the site. The form itself is consistent over time and the form options (elections, jurisdictions, races, candidates) are logical. Each of the results links has a unique postback link. All I needed was a way to parse them and then execute that JavaScript. The parsing part was pretty easy: Python’s popular Beautiful Soup library parses HTML very well, and this was the only form on the page.
The form allows you to search by election, jurisdiction, race, candidate and even by precinct. For example, here are results for the 2nd Congressional District race in 2012 in Storey County. That URL gave me hope: it seemed as if there was a way to construct permanent URLs for each set of results. The trouble was in the pagination—since that’s a postback, the URL doesn’t change when you click on each page’s link. So scraping the form’s results wasn’t going to be simply a matter of looping through each jurisdiction and then building out the proper URLs. Not that I didn’t try that approach first.
Using Beautiful Soup and Python’s requests library, it was trivial to retrieve the URLs for the initial form results and parse the HTML. But executing the JavaScript links was another matter—I always ended up with the same results. Time to try something different. On Twitter, I asked for some advice, and the common denominator was using some kind of headless browser to mimic an actual user bringing up results and clicking on the links. Tom Lee, formerly of Sunlight Labs and now at MapBox, provided one example using Selenium and PhantomJS.
Although a lot of what Selenium gets used for are things such as performing integration tests on web applications—checking that the right things happen when users click on links, for example—the good news is that my use case isn’t all that uncommon. Some web sites are easier to navigate than to scrape. But this was my first time using Selenium, and I ran into some interesting problems along the way.
The basic concept isn’t difficult: you use a library like Selenium to start up a browser (in my case I used Firefox), like so:
from selenium import webdriver
driver = webdriver.Firefox()
driver.get('http://www.nvsos.gov/electionresults/PrecinctReport.aspx')
That will open up the browser and load the precinct form. So far, so good. Most of the issues I encountered dealt with the form itself. After selecting one of the options—say, picking a jurisdiction—the rest of the form would update itself automatically. I could see that when clicking on links, but when I automated it using Selenium, I found it necessary to add in a three-second delay between each form option selection, to allow the form to update before continuing. Selenium has a function for waiting, but Python’s built-in time.sleep() worked fine.
Selecting form elements was fairly straight-forward, again thanks to Selenium. Using the form options found in the HTML source, it was easy to pass in an ID corresponding to a given jurisdiction or race. Using our already instantiated driver object:
import time
from selenium.webdriver.support.ui import Select
election_id = 17 # 2012 general election
jurisdiction_id = 4 # Carson City
election_select = Select(driver.find_element_by_name('ddlElections'))
election_select.select_by_value(election_id)
time.sleep(3)
jurisdiction_select = Select(driver.find_element_by_name('ddlAgencies'))
jurisdiction_select.select_by_value(jurisdiction_id)
time.sleep(3)
That selects the 2012 general election results for Carson City, allowing the form to update at each step. Submitting the form is also pretty simple; a button element has a click() function, and we can pass the HTML from the resulting page to Beautiful Soup for parsing:
driver.find_element_by_name('btnElectionSearch').click()
soup = BeautifulSoup(driver.page_source)
Annoyance
From this point, I figured I’d take the path of least resistance and grab all of the results in a jurisdiction for an election, paging through the links at the bottom of the page.
Grabbing the links wasn’t too hard, but two things made it trickier than I had planned. First, you only get links to 25 pages at a time, and the last link looks like this: “…”, meaning I needed a way to keep track of how many pages there would be for all of the results. I decided to use the total number of results and divide by 50, which is how many appear on each page.
The other problem only became apparent when I tried parsing the larger jurisdictions, Clark and Washoe counties (Clark is home to Las Vegas). There, for reasons I could not explain, the form began throwing errors on the 657th page of results. I needed to add an additional loop for those two counties and iterate over all of the races in each.
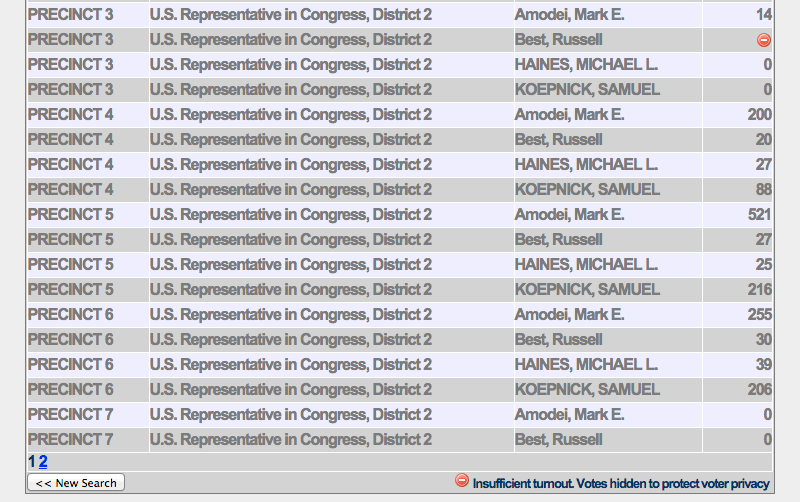
There’s one more wrinkle in the data that I had not seen before: in precincts where fewer than 10 people voted, the results were not shown. Fortunately the image that Nevada uses to display just ends up as a blank space in the scraper’s CSV output.
Acceptance
Once those issues were resolved, I tested out the precinct scraper for the smaller jurisdictions and then did Clark and Washoe separately. Because of my repeated calls to time.sleep() and the need to iterate over more parts of the form in the larger jurisdictions, scraping all of the results took a long time—I completed it in about 30 hours, albeit mostly working from places with less than fiber optic Internet connections. The results are a set of CSV files with precinct-level data going back to 2004 (for good measure, I also scraped county-level results back to 2000). The script to scrape the precinct-level results isn’t particularly clean and repeats itself in places, but it works. And it’s the first public bulk collection of Nevada precinct-level results. The next steps for this data are to get it into OpenElections’ data ingestion and parsing process, and then to generate standardized data for the state.
A few days after I finished running the scraper, my colleague Geoff Hing let me know about Splinter, a Python library that provides a cleaner API for automating browser actions. Were I to start over, I’d definitely try that. More likely is that I’ll find another election results site that works the same way as Nevada’s, and this time maybe I can avoid some of the denial and annoyance and proceed straight to acceptance.
Credits
-
Derek Willis
Derek Willis is a news applications developer at ProPublica, focusing on politics and elections. He previously worked as a developer and reporter at the New York Times, a database editor at The Washington Post, and at the Center for Public Integrity and Congressional Quarterly.


