Learning:
Predicting the Future, Elections Edition
Wherein Jeremy Bowers gets help from experts, builds an election-predicting app, and makes sure readers can see how it works
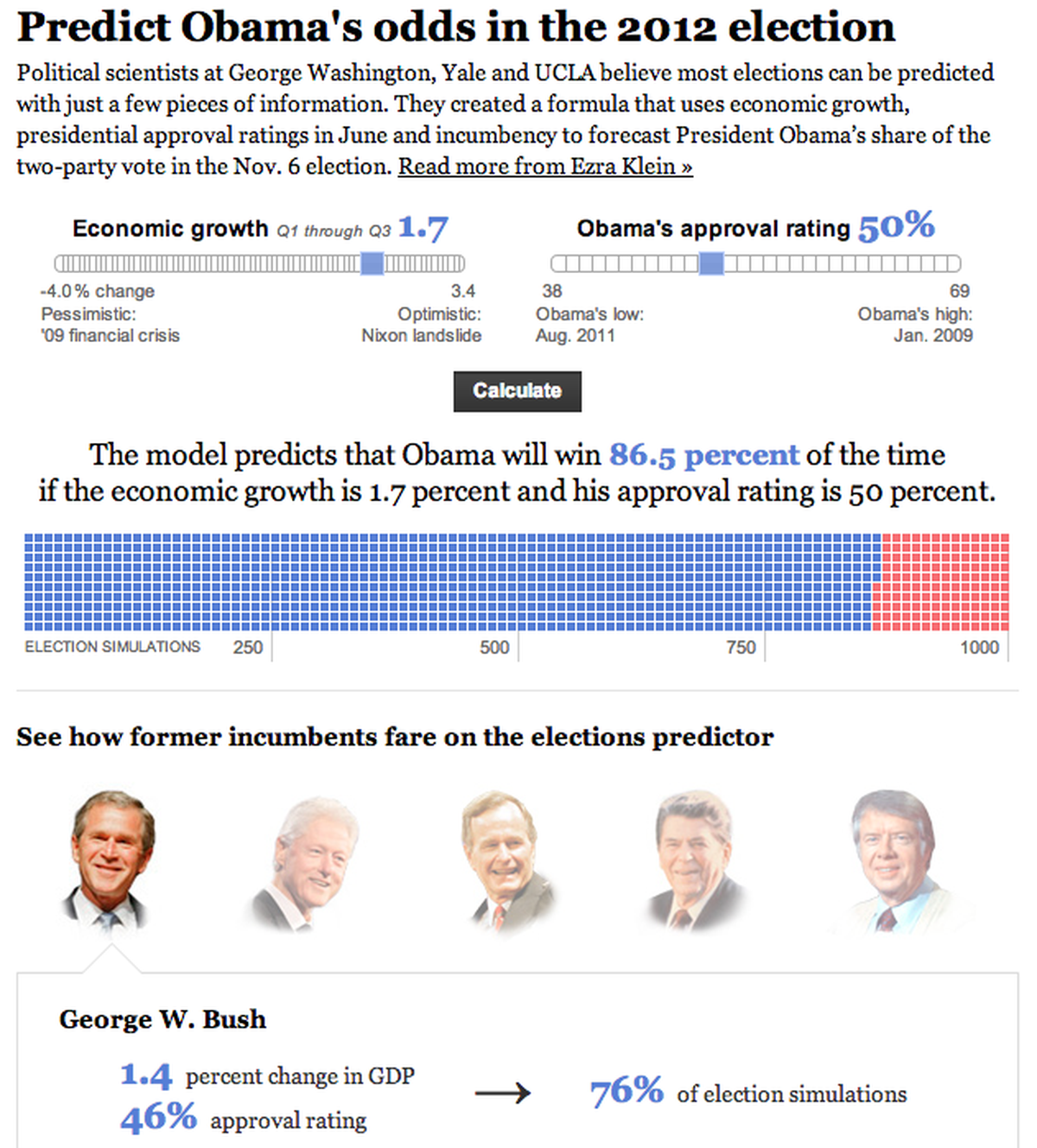
The Washington Post’s election prediction app
Last year, Ezra Klein asked me to build an app that would help him predict the presidential election—in February. And he wasn’t kidding. As a newsroom developer for the Washington Post, I was used to fielding difficult requests. But this one sounded particularly vexing.
What we needed was a statistical model, one that examined previous elections and, from those, allow us to predict the upcoming election.
If you’re like me, you’ve probably read countless stories about statistical modeling and Nate Silver’s deadly accurate FiveThirtyEight predictions. But knowledge about the existence of statistical models is not the same as knowing what’s going on under the hood, as I quickly found out.
What to Do When You’re Not an Expert
Ezra’s the smartest guy in almost any room, but didn’t have the expertise to build a model like this. And obviously, neither did I. But Ezra knew some people who did: political science professors John Sides at GWU, Lynn Vavreck at UCLA, and Seth Hill at Yale University.
Research summarized for us by John, Lynn, and Seth showed that changes in broad economic factors—real disposable income, gross domestic product, or unemployment rate—might explain the results of previous elections, as do factors such as the president’s approval rating and whether or not there is an incumbent president running. If the goal of our model was to predict an election outcome many months in advance, an economic model might be even more accurate than models based on early polls.
What the Heck Is a Statistical Model, Actually?
At its core, the statistical model designed by John, Lynn, and Seth was a mathematical process called a linear regression. Our model sought to measure the relationship between winning an election and some number of explanatory variables. Those explanatory variables were the secret sauce that would set our model apart from others.
To understand what’s useful about a linear regression, let’s take a simple example. One might theorize that there is a relationship between a person’s blood sugar levels and the amount of soda that person consumes per day. Linear regression lets us measure just how strongly someone’s soda consumption affects their blood sugar levels. But there may be other lurking variables that are related to both soda consumption and blood sugar and therefore complicate our ability to estimate the association between them. For any arbitrary person’s blood sugar levels, lurking variables like their family medical history or their metabolism might influence the results. Moreover, any inferences about the relationship between soda consumption and blood sugar could be tenuous without enough data: larger samples provide more precise estimates of statistical associations, other things equal.
If soda consumption explained everything about blood sugar levels, we’d say that they were perfectly correlated—in other words, we could say that our R and R-squared were 1.0. If other variables like family medical history also mattered, the R-squared value might be 0.50. In this case, it would mean that soda consumption only explains about half of the variation in blood sugar levels between people.
The neatest part about a good statistical model is that we can make forecasts, in this case about people for whom we have soda consumption data but not their blood sugar levels, but it’s the general capacity for forecasting that got us excited.
Our Model: the Secret Sauce Revealed
So back to the election. More conversation ensued, and we reached the first decision point: What was going to be in our model?
Many economic indicators are associated with election outcomes. John, Lynn, and Seth relied on change in gross domestic product (GDP) between January and June of the election year—basically an overall measure of the health of the nation’s economy. In addition, our model drew on the president’s approval rating as of June of the election year, and whether the incumbent president was running for reelection.
Our model had three key advantages. First, it drew on existing theories about how a crucial subset of voters makes up its mind, since health of the economy and presidential approval are key indicators for evaluating the performance of the incumbent party. Second, it drew on things that could be measured well in advance of the election, since using measures from right before the election would not make for a very interesting forecast. Part of our goal was to attempt our prediction well in advance of the election. Finally, it relied on a small number of factors rather than trying to identify factors that might account for every idiosyncrasy of individual elections.
When this model was run against the 16 presidential elections between 1948-2008, this combination of variables explained about 80% of the variation in election outcomes. Other unmeasured factors therefore accounted for the remaining 20%. This is typical for many election forecasting models, and gave us confidence that this model would produce a reasonable forecast.
Settling on a model was just the first step. Next, we had to come up with a way to implement it that would work with the flood of traffic that would be coming to our news application from Ezra’s blog and the Washington Post home page.
The Devil Is In the Details
The goal all along was to build a news application that would let readers plug in their own values for the GDP change and predicted approval rating and see how the results of the election changed. We couldn’t just bake this out to flat files and weather the storm—we’d need to find some way to do dynamic calculation since we would asking our readers in April to forecast the GDP change between January and June and June’s presidential approval rating.
We quickly figured out there there was no way that we could handle the flood of traffic coming from loyal Wonkblog readers if we had to run our model with every request.
After some discussion, Seth came up with a winning idea. He would simulate the model 1,000 different times. Because our estimates of the effects of GDP, approval, and incumbency had some statistical uncertainty associated with them, each simulation would generate slightly different estimates. He would dump these into a CSV, one line for each of the trials. We could then replay the model given any arbitrary values for GDP change and presidential approval. Instead of running the model 1,000 times with each request—and melting our servers into slag—we would merely add some numbers together.
Here’s some example rows from Seth’s CSV:
intercept,b_gdp,b_approval,b_incumb,error 35.31582,0.6771413,0.3064282,2.17408,2.519898 37.73929,1.501397,0.1629183,5.550177,3.816859 30.80339,1.519786,0.3728411,1.493553,-1.273699 34.39424,1.394472,0.2904536,1.165239,2.800546 35.47057,1.174212,0.2675007,2.782254,-1.774582
Time to put on our math hats, people. The intercept is simply the value of presidential vote share when the other variables in the model were equal to zero. It’s actually no different than the intercept in the standard equation for a line that you learned in algebra class—you did take algebra, right? The variables whose labels begin “b_” capture the association between each factor and vote share. To continue tormenting you with more ninth-grade algebra, these are the “slopes.” The “error” column represents the underlying uncertainty about the model’s forecast—that is, how much the forecast could be off because of random chance. We assumed that this error came from a particular statistical distribution—a t-distribution, for those reading along at home—under which large mistakes are somewhat more likely than under a standard normal—aka “bell curve”—distribution. This is a standard statistical practice in prediction exercises to allow for the greater uncertainty in predicting new events. With all of that in mind, our equation looked like this:
vote share = intercept + (b_gdp * user-selected gdp value) + (b_approval * user-selected approval rating) + b_incumb + error
For each of the 1,000 rows in Seth’s spreadsheet, we’d plug in the values and run this equation. If the result was greater than 50, it meant that the incumbent won that particular trial; if it was less than 50, it meant that the challenger had won it instead. When the 1,000 runs were finished, we’d add up the win-loss totals for the incumbent and the challenger and it would represent a forecast—if the incumbent won 673 of our 1,000 trials, we could report, “Under these percent change in GDP and presidential approval conditions, the incumbent wins 67.3 percent of the time.”
Running the full linear regression above for this data took between three and four seconds on our server. Having to repeat that 1,000 times for every visitor to the site is the stuff that nightmares are made from. Seth’s changes meant that we could run all 1,000 trials in a few milliseconds. That’s the kind of performance which meant I could sleep at night without getting phone calls from our support staff asking why our servers were on fire.
Always Be Testing
Now we had a good theoretical model and a practical implementation of it. But before we even started brainstorming about what our news app would look like, I needed to smoke test the results. I put together a page that would let us plug in values for percent change in the GDP and a predicted June approval rating and return the result.
I wrote up three scenarios based on some research and checked the numbers. The results seemed very wrong.
For example, in the scenario where GDP growth dropped slightly to 1.5% and the President’s approval rating dropped 5% below his (then) 49% average, he still won 72% of our simulations. This made my “something is wrong” spidey-sense tingle. I emailed John and asked him to double-check our math, thinking that I had improperly implemented the model somehow.
But the results weren’t wrong. John explained that this was an interesting conclusion that our model had illuminated: It’s really hard to unseat an incumbent president. In fact, the challenger doesn’t start winning a majority of the trials until the GDP growth declines to an incredibly stagnant 1.1% and the president’s approval rating declines to 39%. Even in that fairly bleak scenario, the challenger only won 508 of 1,000 simulations.
Just Build the App Already
Now that we had a working model and we felt confident in the data we were getting back, we needed to build our news application! Post Graphics editor Emily Chow, Ezra, and I settled on sliders for GDP growth and approval rating. And after some basic reporting, we set the sliders to the sensible defaults of 1.7% GDP growth and 49% approval rating. Without those defaults, Ezra’s readers would have no idea what reasonable choices for GDP growth and approval rating should be.
In addition to offering election results information, Emily and I desperately wanted to show the inner workings of a model based on linear regression without boring our readers. It’s important for readers to understand what they’re doing when it comes to playing with statistics. Emily decided on a visual treatment where we drew a cube for each of the 1,000 trials, demonstrating at a glance how the model worked. The wonder of a regression is that it runs multiple trials and then aggregates the results from each one.
This required that I build a JSON API to back our news application that would return results for each of the 1,000 trials. I decided to include a schema with the results so that anyone reading along at home could see what each of the fields meant.
For the last piece of the interactive, Ezra ran the model against some former incumbent presidents—Carter, Reagan, George H.W. Bush, Clinton, and George W. Bush—to demonstrate how the model explained previous election results.
The Morals of the Story
So, that’s our story. But what’s a story without some morals? Here are five things to remember when you undertake your next data journalism project:
- Seek out expertise: You’ll invariably end up building something that’s out of your realm of knowledge. Don’t let this stop you: Find experts and get them excited about what you want to build.
- Build a prototype and test your results: You’ll either find your grievous errors ahead of time or you’ll find surprising results from your data. Either way, you’re a winner.
- Precompute anything you can: Do as little work on each request as possible if you’d like your servers to refrain from melting into slag.
- Scenarios and sensible defaults: Readers are smart, but they need context to use your interactive. Set up scenarios and sensible defaults so that people know what reasonable settings for your model are.
- Loosely couple your data to your application: Building an API to return results and mocking up example JSON for your graphics designers makes iteration easier and the final result more flexible.
Credits
-
 Jeremy Bowers
Jeremy Bowers
Jeremy Bowers is a developer on the Interactive News Team at The New York Times and previously worked for NPR, the Washington Post, and the St. Petersburg Times. He spends his weekends watching baseball and obsessively honing his ramen broth. As a college debater, he spoke more than 600 words per minute. (Photo credit: Claire O’Neil, NPR Visuals.)


