Learning:
Finding Stories in the Structure of Data
Matt Waite sees structure in unstructured data, and you should too
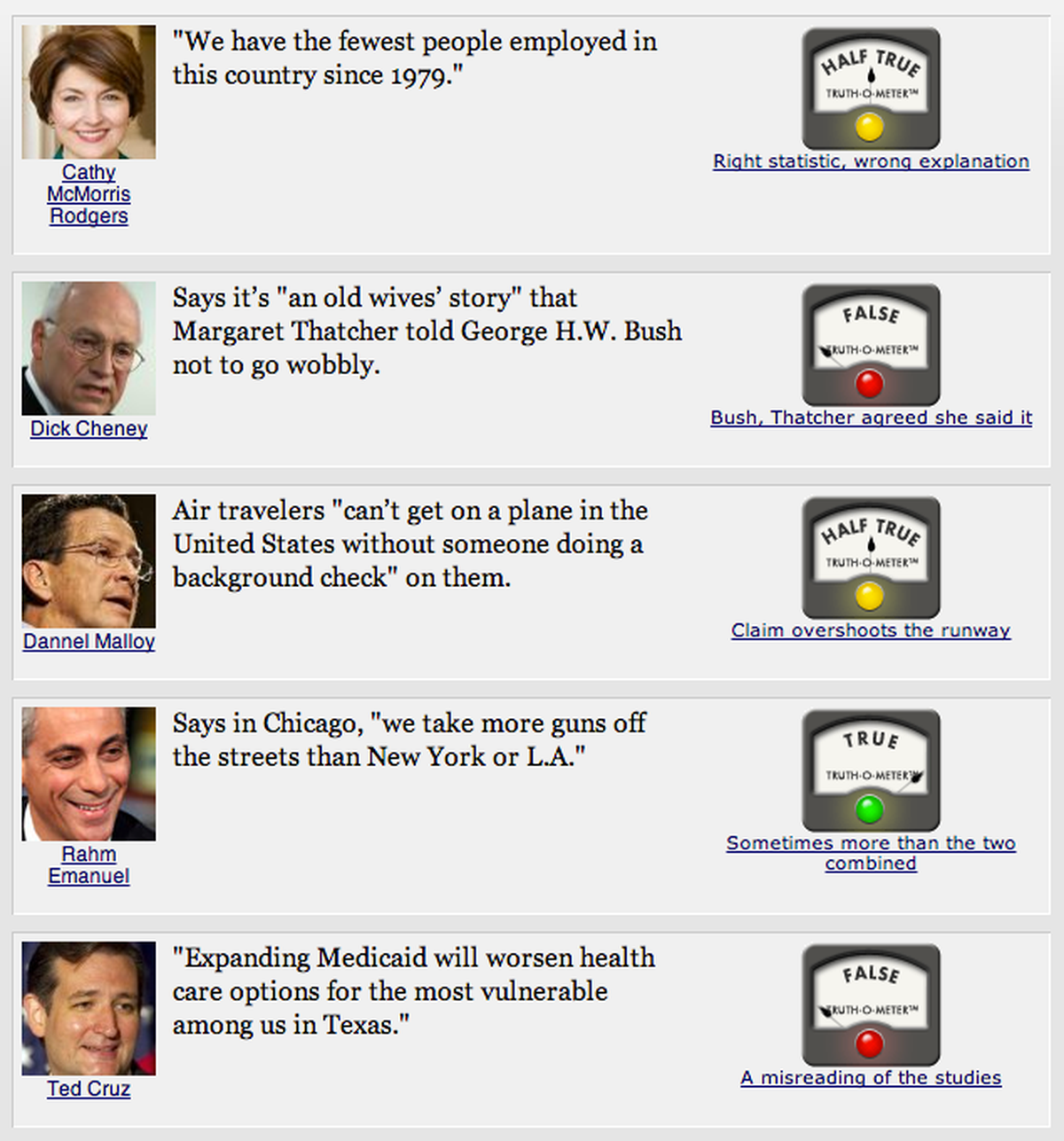
PolitiFact scores
We’ve been telling stories since we invented language. You can imagine hunter-gatherers sitting around the fire talking about the hunt, or the direction of the herd, about the coming winter or whatever it was we needed to talk about in order to survive. We’ve become pretty good at telling stories over the millennia.
So I’m not here to tell you that stories are going away. That they’re dead. They’re not. To think so is arrogance.
I’m here to argue that our vision of a story is too simple and wholly inadequate for the web.
Much of our conception of what a story is on the web comes from print newspapers. There’s a headline or title and there’s the place you put all the stuff. Oh, sure, with blogging we’ve added things like tags and categories and photos, but we’re still in this one-size-fits-all model of just dumping stuff into a big box. And, if I’m building a content platform, then I have to be generic and cover the most stories that I can.
But is that the only way we can tell stories? Is generic the only path?
Look for the Nouns
Sure, every story we tell online has the same generic format that online news inherited from newspapers—headline, body, etc. But what if we looked a little deeper, focused a little more? What would we see?
We’d see more structure in each story we write. We’d harness more data out of our narrative, isolate what’s useful and use it. In a word: Nouns. We’d take nouns from our story—like “crime“ or “Downtown” or “theft” or “Congressperson”—and make them database fields. Nouns are useful, so let’s use them. Let’s use them in a way that explodes traditional narrative formats.
For the record: This isn’t my idea. This is Adrian Holovaty’s. And he saw this coming in 2006. He argued that using structure would allow us to repurpose stories into other useful things. You should read his words, because they were what inspired me to take this idea of structure and run with it a bit. It was the idea that guided me building PolitiFact in 2007, a site that remains an ongoing experiment in storytelling, entrepreneurship within a news organization and journalism, and it’s an example of what I mean by telling stories from structure. PolitiFact started as an idea for how to cover a presidential election differently than everyone else, and spun up into an exercise in using structured journalism to track truth in politics. PolitiFact scores things politicians say on a six-point scale of truth, from True to Half True to Pants on Fire! wrong.
Traditional news organizations, at least until recently, didn’t do this. They wouldn’t call a lie a lie. The traditional model is to “present both sides” and “let the reader decide.” PolitiFact turned that on its head with the idea that it was our job to make a call. And, because we were playing with the structure of news, it allowed us to try some new things, like listing our sources or collecting a person’s scorecard.
When PolitiFact was named the first website to win the Pulitzer Prize, in the category of National Reporting in 2009, you’d think that a torrent of structured, data-driven websites would have been unleashed on the world. Right? Wrong. Oh sure, there are a few exceptions here and there. But the vast bulk of news on the web remains in the same structure it was 10 years ago. News organizations are still failing to harness the underlying structure in what they do to fundamentally change the way they do business.
It’s an opportunity to exploit.
What Do You Mean, Structure?
Let me tell you a tale of two crimes.
One involves my first house, a 1,200 square-foot ranch in Largo, Florida that had a big lawn and friendly neighbors. One of those friendly neighbors had the same sickness I do, in that we both cared deeply about how our lawns look. So every weekend, we’d be outside in this unspoken competition on who had the nicer lawn. One day, he left his garage door open and someone stole all his lawn equipment. He was a friend, and an attack on him was an attack on me. I cared deeply about that crime. It happened on my turf.
The other happened miles and miles from my house, in a different kind of neighborhood. It was a classic love story of boy meets girl, boy and girl date, girl breaks up with boy, boy takes a machete and cuts off new guy’s head off, boy puts the head on a car and waits for the cops to show up. You know, fairy tale stuff.
These two crimes, as different as they are, have the exact same structure, but newsrooms don’t think of them this way. Sure, they have a headline, but more importantly they have a date and time, a location, a crime type, a victim, maybe a suspect, and a narrative of what happened which includes all those data points. Those pieces of data could be used to create something much bigger and better than a crime blog. They could create a meta-story out of the collection of individual stories, all derived from structure.
If you think about it long enough, nearly every routine kind of story that journalists cover has a structure. Fires, car accidents, government meetings and crimes, sure. But what about sports, wedding announcements, obituaries, local festivals and business openings? If you could harness that structure, you could show people things that would be considered stories, aggregated by being near their house, or, slicing it differently, by type of event (like thefts), or by demographics, instead of by local proximity.
What’s the first step here? The question is: how do you get structure from the common unstructured narrative?
Automatic or Manual?
Really, I think there are two warring factions here: Automatic and Manual (or, as I prefer to call it, artisanal, hand-crafted data). The truth, like all things, is that you can blend these approaches, but let’s look at the extremes so we understand.
The argument that you’ll get from newsrooms is that it takes so much time to write and report and edit that we can’t possibly do anything else. That would just be too much. So, a reasonable approach to wanting more structure from unstructured data is to write algorithms that extract that data.
And indeed, given enough time, you can extract structure from the unstructured. Using an entity extraction library like Open Calais, you can find things like businesses and people in stories and connect them to other pieces of information, should you want to. Or, a more recent piece of whimsy, fellow OpenNews Learning writer Jacob Harris extracted Haikus from New York Times stories. One of the really neat features of the now-defunct Everyblock, a site that began life as a block-level data and news aggregator and evolved into a neighborhood level social platform, was that it found street addresses or locations in text and geocoded them automatically (though, Holovaty has said lots of hand geocoding went on).
On the other end of the spectrum sits PolitiFact. PolitiFact has no automated data extraction systems (though I have played with a few). The connections between speakers and statements and subjects and elections goes on all by hand. Journalists assemble a fact check item piece by piece, connecting structured data to the story by hand. Without a single question mark on the page, it acts like a series of questions: Who said this? What did they say? Where did they say it? Is it true? False? Between? And why is that?
Either way, automatic or manual, in structuring our data, we’re seeking to answer questions people have. The choices we make should start with those questions.
In Praise of Simplicity
Every time I talk about PolitiFact—five years, three continents, two hemispheres, tens of thousands of miles and counting—I tell the same joke. It goes like this:
There’s only one Barack Obama. There’s only one John Boehner. There’s only one Nancy Pelosi, Harry Reid, Rush Limbaugh, or Bill O’Reilly.
Thank God.
(Thanks, here all week folks!)
The reason I say that is because it’s true: there is only one Barack Obama. Why would your data structure suggest otherwise? Why would you ever type those names in manually? Or create a data structure where there’s two Barack Obamas in two tables unrelated to each other?
Computer scientists and data people have a process called normalization, where there’s a table of a thing, and that thing gets related to other tables that need to reference that thing. That way, all that’s being stored in the other tables are references to this thing—the relational parts of a relational database system. This is exactly how I set up PolitiFact. There’s a people table, and they say things (the statement table), or promise things (the promises table) or they get mentioned in stories (you guessed it; there’s a stories table). These kinds of relationships don’t exist in most newspaper content systems.
If you’re unfamiliar with normalization, let me put it into story terms. We want our database to mimic real life. Real life has a table called people, and there’s only one of each of us in this table. Our people table has information about us—our name, our age, etc. Then, whenever anyone mentions us in other data, they just refer to us by our people table record instead of writing out our name and information about us that they need. We already have that. Just pull it from the table.
In PolitiFact, people, subjects, rulings, authors, editors—all have table relationships. Why do this? Lots of reasons. Database efficiency. Relationships we can query. All that. But a simpler one? It makes people’s jobs easier to just pick a name than to type it. Make someone type their own name 1,000 times, they’ll spell it wrong eventually. I’ve had to clean legacy data in old systems that didn’t normalize data and people found 11 unique ways to spell “Tampa,” a five letter word.
So your data should model real life. If there’s only one of each team, make a team table and relate that to games, which relate to seasons (among other things). If you’re tracking speakers, make a speaker table and relate them to things they say (because they’ll say lots of things, but there’ll never be more than one of them).
One of the foundational ideas behind how PolitiFact was built is that there is a URL for everything. Want to see all Pants on Fire rulings? Sure. Everything ever done on Taxes or Baseball? Done and Done. Want to see Barack Obama’s page? Here you go. Or every Pants on Fire the President has ever received? We’ve got you covered. All of that comes from the structure. Simple urls, clean data to query, logical patterns to everything—it all comes from that structure that we started with.
The possibilities of applying this same idea are endless.
Take the Structure and Run
I see two opportunities here.
- Build websites on this structured approach and start feeding the beast. Rebuild journalism to interest a particular audience using the structure of that topic to drive the whole thing.
- Build tools that could integrate these ideas into existing publication systems without having to hack away at them. Popup screens that can be added into workflow that feed a data backend that have API endpoints that allow designers to pull structured data into unstructured places like stories. The whole area of non-relational data stores like MongoDB and their ilk has fascinated me in this regard. How could a schemaless system be brought in to bring structure to the unstructured? Just writing that sentence makes my head swim in both good and bad ways.
But the broader challenge is to think about how a little data-thinking could fundamentally alter how stories get made and told on the internet. I believe there is fertile ground to plow here. Lets get to thinking.
People
Credits
-
 Matt Waite
Matt Waite
Matt Waite is a professor of practice in the College of Journalism and Mass Communications at the University of Nebraska-Lincoln and founder of the Drone Journalism Lab. Since he joined the faculty in 2011, he and his students have used drones to report news in six countries on three continents. From 2007-2011, he was a programmer/journalist for the St. Petersburg Times where he developed the Pulitzer Prize-winning website PolitiFact.


